How to Make Headphones Stereo-Compatible

Have you ever wondered why music sounds so different on headphones compared to loudspeakers? It’s because, by design, headphones are not technically compatible with the stereophonic system. That isn’t to say you can’t still get great sound from headphones. Otherwise we wouldn’t be seeing the boom in headphone sales that we’ve been seeing the past few years (although it’s worth pointing out that some retail stores keep mirrors next to the headphone displays for customers who care more about looks than sound). In this post, I’ll be examining why music sounds different on headphones, and look into a technology that can upgrade headphone sound quality by several notches.
Why headphones are incompatible with stereo
When you listen to music using headphones, you will notice that sound can generally be perceived as coming from inside your head. And when an instrument is playing only in one channel, you get the uncomfortable sensation that the instrument is playing just next to your ear.
In loudspeaker playback, the sound stage is naturally rendered between the loudspeakers. When you sit in the sweet spot, the loudspeakers are typically 45–60 degrees apart in a normal stereo setup.
The fundamental difference between loudspeaker and headphone playback is that with loudspeakers, the sound from one channel reaches both ears (as you can see in Figure 1a below). Whereas with headphones, we usually just send the left channel to the left ear and the right channel to the right ear for the simple reason that we have two audio channels and two ears. But it’s possible to think one step further than this.
Cross-feed: Loudspeaker simulation using headphones
Many people like the sound of headphones, and many even prefer it to speakers. When you use headphones, you get rid of all the room coloration and you tend to get a very big sound stage—even though it’s basically inside your head.
Having direct access to the ear signals, as you have with headphone listening, gives a lot of freedom when it comes to applying digital filters to shape the sound. You can simulate virtual sound sources anywhere. You can even simulate a normal stereo speaker setup. But most listeners will probably prefer something between the loudspeaker and the headphone experience, maintaining the best of both worlds—low coloration, and a big coherent sound stage right in front of you.
It is possible to make headphone listening a lot more similar to loudspeaker listening, however. The way to achieve this is by implementing what is commonly known as cross-feed, i.e., some of the left channel is fed to the right ear and some of the right channel is fed to the left ear. There are several products on the market that do this, and most try to simulate the experience of listening in a room by adding room reflections to the sound. A typical application would be to simulate a surround sound setup with virtual speakers placed around the listener. However, adding artificial reverb to the sound always introduces some form of coloration. In this post I will focus on the objective of obtaining the highest possible sound quality for stereo sound recordings, achieving a natural headphone sound without simulating a room. Let’s say we want to simulate a normal speaker setup, as shown in Figure 1a. Then we would need to add directional cues to the headphone signals so that the brain understands where the sound is coming from.
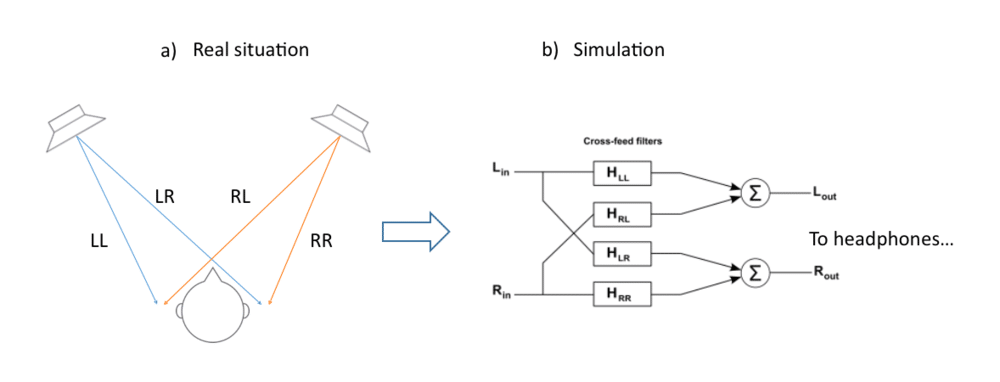
Figures 1a and 1b: a) Illustration of the natural cross-talk that occurs between both speakers and both ears when listening to loudspeakers. b) A cross-feed network for headphone simulation of the cross-talk in Figure 1a.

Figure 2: Response at the ear canal openings of both ears for a speaker placed at 30 degrees relative to the listener (LL=left speaker to left ear, LR=left speaker to right ear).
In order to know what those cues are, we need to analyze the way sound is affected as it travels from one loudspeaker to each ear. Looking at Figure 1 a, we can see that the sound from the left speaker will reach the left ear first and then, with a small delay (about 0.27 ms if the speakers are placed 60 degrees apart in a normal stereo triangle), reach the right ear. This delay is one of the cues that tells the brain where the speaker is located.
A detailed picture of what it looks like when the sound reaches the ears in a speaker setup can be established by taking an acoustical measurement at the ears of a listener. By putting microphones in the ear canals of a listener who is sitting in the sweet spot of a speaker system, and measuring the response from one loudspeaker to both ears, curves similar to those illustrated in Figure 2 can be recorded. This is called a Head Related Transfer Function or HRTF, for short. The curves show how different frequencies are either boosted or attenuated at the ears of a listener. As you can see, they are far from flat, so the head, pinna, and torso have a large effect on how we perceive sound. The exact pattern of peaks and dips in these curves is different for both different listeners, and different sound source locations. This spectral coloration is analyzed by the brain to find out where the sound is coming from.
If we take this measurement and make a digital filter from it, we can simulate the ear signals that would result from any music signal being played back on the loudspeaker. The digital filter network in Figure 1b can implement these filters, including the correct time delays, to simulate the ear signals of a loudspeaker setup, thus giving a similar experience.
Are we ready to step into audio nirvana then? No, not really. If we were to implement the cross-feed network using only the above measurement we would, on the one hand, get a more natural and comfortable sound stage that’s more similar to loudspeaker listening. On the other hand, we would also get a spectrally colored sound that would ruin most of the fun. That’s partly because headphones are usually already made to sound as flat as possible. So introducing more EQ to the signal path is not a great idea (at least not if you lack measurements on the headphones). Also, HRTF responses are very different from person to person, so it doesn’t make sense to include any spectral detail in the HRTFs used in the cross-feed network.
We can EQ the HRTFs for a more uncolored response, and we can use average HRTFs derived from a group of people. Doing this, we’d end up with something like that which is shown in Figure 3. The difference in level between the left and right ear is the most important cue our brain uses to determine location, and this cue is kept intact even if the same EQ is applied to all the filters in the cross-feed network.
If you read my previous blog post, Under the Hood of the Stereophonic System: Phantom Sources, you will recall that the difference in the arrival time of sound from one of the speakers to each ear gives rise to a disturbing comb filter effect, or coloration, for sounds in the music that are panned towards the center of the sound stage. Therefore, it is not a very good idea to implement this time difference directly in the cross-feed network. Dirac’s version of cross-feed instead implements a patent pending method which includes the time-difference cues without giving comb filtering.

Figure 3: Cross-feed filters based on HRTFs with some equalization applied to make the response smoother without affecting the relative amount of cross-feed at different frequencies. (LL=left channel to left headphone, LR=left channel to right headphone)
Reproducing room sound in stereo
Consider this a bonus section for advanced readers. Somewhat simplified, music can be said to consist of two types of sounds. One is instrumental sound, which is clearly defined in the sound stage, and the other is diffuse reverberant sound, which does not have a specific direction. Reverb sound provides psychoacoustic information about the dimensions of the recording venue and provides a nice sense of envelopment.
How well does a stereo system reproduce the reverb sound in a recording? To answer this, we first need to obtain a reference measurement from a real recording venue. Well, since it’s difficult to find a situation where we only have reverb, we’ll do a simulation instead. Let’s pretend we have a very big room with thousands of loudspeakers placed evenly around a listener, and the speakers are each playing a random noise. Now we have what is called a diffuse sound field. It’s similar to what reverb sound is like in that an equal amount of random sound comes from each direction. Next we’ll place a listener in the room with microphones in their ears. What we’re interested in learning is, how different is the sound at the ears? The more different it is, the bigger and wider, and more enveloping the sound is perceived to be. We can use the measure of correlation to find this out. Correlation is a measure of the similarity between two signals—a value of 1 means they are identical, and 0 means they are totally different. Conducting this measurement in the simulated room gives us the blue line we see in Figure 4, which shows the correlation as a function of frequency (also called binaural coherence). We can see that in a real situation, the reverb sound in a room would be totally different at the ears at high frequencies, but identical at low frequencies.
How about if you listen, using headphones, to a recording taken in a room with lots of reverberation? If you put two omnidirectional microphones in a recording venue with enough distance between them, the recorded reverb will have very low correlation between the channels—that is, it will be very different. When listening to the recording using headphones, the reverb sound will have much lower correlation at low frequencies than what is possible in real life. This does indeed give an unnatural quality to the sound.
In a loudspeaker setup, the situation is much better. Figure 4 shows the correlation at the ears for two different loudspeaker setups playing the reverb sound recording. The red line is for the standard stereo triangle with 30 degrees to each loudspeaker, and the green line is for an angle of 35 degrees to each speaker. We can see that below about 600 Hz, the loudspeaker playback gives approximately the same correlation at the ears as a listener would experience in the actual recording venue, which means sensations of envelopment are reproduced correctly.
In the case of the loudspeaker, and the same applies to a normal cross-feed implementation for headphones, the correlation starts to increase again above 600-1000 Hz. This is not as bad as one might expect, since ours ears are much more sensitive to correlation and phase differences below about 1000 Hz. Nonetheless, it does give some unnatural character to reverb sound. For this reason, Dirac’s cross-feed implementation addresses this problem and gives the same correlation between the ears for reverb sound in the recording as a listener would perceive in a real situation.

Figure 4: Correlation between ears versus frequency for different scenarios.
Pure cross-feed as discussed here is currently not featured in any Dirac product out on the market. But it is a fundamental building block of Dirac Sensaround, which is a technology for simulating surround sound over headphones. Dirac Sensaround also simulates a virtual listening room which improves the experience of the sound coming from outside the head.
I hope this post helped shed some light on what cross-feed for headphones is all about. Feel free to post a question or comment!
– Viktor Gunnarsson, Senior Research Engineer at Dirac Research